Greetings. I am a historian of American religion and the nineteenth-century United States, often using computational methods for texts and maps. I serve as the executive director of the Roy Rosenzweig Center for History and New Media, a research center which creates websites, podcasts, educational resources, data-driven histories, and other open-access digital work to democratize history. I am also a professor in the Department of History and Art History at George Mason University.
More information
Around the internet
- Bluesky
- GitHub
- GMU faculty page
- Google Scholar
- Humanities Commons
- Micro.blog
- Observable
- ORCID
- Zotero
Contact me
Feed
Writing. If you would like to follow my work, the blog is the best place. It includes blog posts, shorter link posts, and the archives of my newsletter. You can subscribe to everything either by adding the site feed to a feed reader, or by subscribing to my newsletter.
Subscribe to the “Working on It” newsletter
American religious history, digital history, and the making thereof
If you want to follow our work at RRCHNM, please subscribe to our newsletters. My social media accounts are listed in the sidebar; I mostly use Bluesky these days.
Teaching. My courses cover American religious history, the history of Christianity, the history of the nineteenth-century United States, and digital history. All of my syllabi are freely available.
Visualizations and software. While working with computational methods, I often create visualizations or software. The best place to find the visualizations is embedded in my scholarship. The source code for visualizations and software packages are all open source and available from my GitHub profile.
Scholarship. My scholarship is often collaborative. I have the good fortune of having collaborated with many of my colleagues at RRCHNM, and each of the project websites credits contributors fully. But I would be remiss not to mention that I have had particular fruitful collaborations with John Turner in American religion and Kellen Funk in American legal history.
For a full list of my work, please see my CV. Below is a list of my books (print and digital) and some of my collaborative digital projects, with an emphasis on ongoing work.

Antisemitism, U.S.A.
A podcast on the history of American antisemitism
Generously funded by the Henry Luce Foundation, this podcast will be released in June 2024.
How can Americans overcome a problem that they can’t define, a bigotry whose particulars shift over time, a hatred that most consider a problem of the past rather than the present? RRCHNM’s podcast explores instances and aspects of antisemitism in U.S. history through narration, primary sources, and expert interviews. These stories will discuss what antisemitism is and how it developed and persisted alongside other forms of bigotry and hatred in the United States. Episodes will relate to the podcast’s broad themes: that antisemitism is a deep-rooted American problem, that it spans the political and religious spectrum of the United States, that it is intertwined with the history of race in America, and that knowledge and understanding of the history of American antisemitism makes it easier to identify and oppose it in the present.

America’s Public Bible: A Commentary
Stanford University Press, 2023
America’s Public Bible is an interactive scholarly work that uncovers the history of the Bible in the nineteenth- and early twentieth-century United States. Using computational methods, this project has found biblical quotations in two large corpora of historical American newspapers. By identifying, visualizing, and studying quotations in American newspapers, the site offers a commentary on how the Bible was used in public life over one century of American history.
Winner of the 2016 National Endowment for the Humanities Chronicling America Data Challenge
America’s Public Bible project website Stanford University Press catalog

The Chance of Salvation: A History of Conversion in America
Harvard University Press, 2017
The United States has a long history of religious pluralism, and yet Americans have often thought that people’s faith determines their eternal destinies. The result is that Americans switch religions more often than any other nation. The Chance of Salvation traces the history of the distinctively American idea that religion is a matter of individual choice.
Winner of the American Academy of Religion’s 2018 prize for Best First Book in the History of Religions: “Mullen takes a common trope about American religions—that they are about conversion and choice—and deploys it in astonishingly illuminating ways across the breadth of religious traditions. … Mullen clearly and convincingly demonstrates how pressures to convert changed the foundations of American religions. … This book is innovative, accessible, highly teachable, wise and mature.”

American Religious Ecologies
Datasets and visualizations for American religious history
The American Religious Ecologies project is creating new datasets from historical sources and new ways of visualizing them so that we can better understand the history of American religion.
We are currently digitizing the 1926 Census of Religious Bodies. At the start of the twentieth century, the U.S. Census Bureau surveyed the nation’s “religious bodies.” These congregation-level schedules—some 232,154 of them—are a treasure trove of congregation- and place-specific data.
We are also transcribing the 1926 census into a dataset, and mapping and visualizing the data. These efforts contribute to a fuller and more vivid depiction of the religious landscape of the early twentieth-century United States.
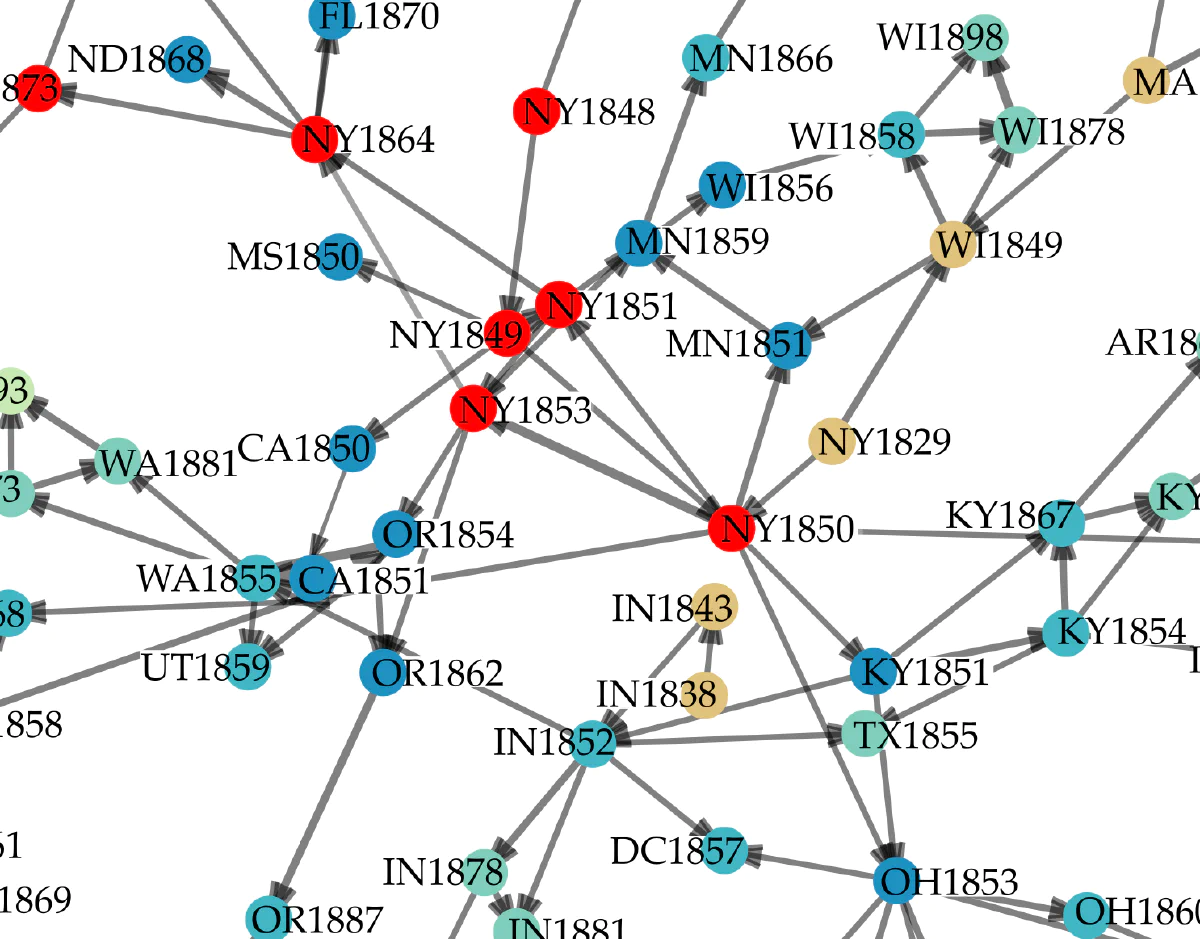
Legal Modernism
American legal history through computational methods
Law and legal practice modernized in the nineteenth-century United States. The textual record of legal modernization is vast. Hundreds of volumes of regulations were formulated, copied, and re-formulated by legislatures. Millions of case reports became the authoritative building blocks for the thousands of treatises from which modern American law was constructed.
We are studying and visualizing the history of the modernization of American law through computational methods.
More information
Around the internet
- Bluesky
- GitHub
- GMU faculty page
- Google Scholar
- Humanities Commons
- Micro.blog
- Observable
- ORCID
- Zotero